
A look at Florence-2 for Vision Tasks at the Edge

Craig Nielsen
February 26, 2026
An exploration and labelling model, that supports many combined vision and language tasks out the box.
Florence 2 supports many tasks out of the box:
- Caption,
- Detailed Caption,
- Dense Region Caption,
- Object Detection,
- OCR,
- Caption to Phrase Grounding,
- Segmentation,
- Region proposal,
- OCR,
- OCR with Region
Florence 2 is an AI model built by a team at Microsoft. Most other models are specific and can perform tasks (from the list above) very well, so the MS team decided to automate labels and use those existing models to build out a larger combined dataset. The dataset is very comprehensive and contributes more to the value of this model than the architecture itself.
The use of this model could be for quickly one-shot as a proof of concept during development but there-after you could fine tune a YOLO model in a specific use case. IE: Florence-2 is best used as a development and annotation tool, not your production edge model. There are also options for fine tuning the Florence2 model though, here is an example: https://huggingface.co/blog/finetune-florence2 For example you could use this model to label training images and then use those labels for fine tuning a YOLO model, which would perform better, faster and cheaper because there is no use for the langage components of the larger model at that stage.
Running on edge devices
Jetson AGX Orin (the top-end Jetson, ~$500) - Florence-2 base (0.23B) runs fine with TensorRT optimisation. The 0.77B model is pushing it for real-time use but workable for non-time-critical tasks. This is genuinely deployable.
Jetson Orin Nano (~$250) - Florence-2 base (0.23B) with aggressive quantisation (int8) can run, but you're looking at 500ms –> 1s+ per inference. Fine for some use cases, too slow for a fast production line.
Raspberry Pi 5 - Florence-2 is basically a no. It has no NPU worth speaking of for this model size. You'd use it for other things in your stack (connectivity, OTA, orchestration) but not inference of a VLM.
Development and training: Cost Comparison (WIP)
During development, many on demand GPU's have reasonable pricing but you might make costly mistakes.
Lets look at the usecase for "brainstorming" with Florence2, and finding something that you can eventually fine tune into a YOLO and push into production.
For this specific use case — first fine-tuning experiments, scrappy validation, not a production training pipeline.
A pipeline for pipelines
This is a work in progress diagram you could use to visualize the process end to end. Each step requires some work and could be viewing in order as somewhat of a roadmap to get to a product.
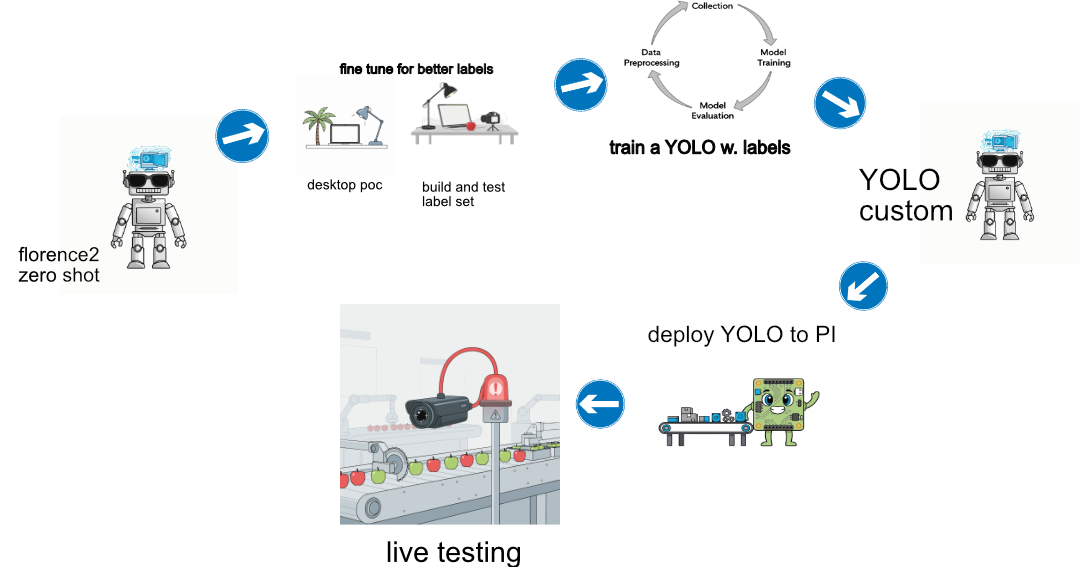
To start you could stay in Florence2 zero shot land, test different inputs and setup a flow for what to do if you need better labels (fine tuning in Florence2 land).
Once you are happy that the labels are being generated and you are happy, you need to build a bunch of training images, then generate labels for those with your new fancy Florence2 model.
Now you have a training set.. which you can use to -> train a YOLO.. cheaper more specific and can run on the edge hardware. This process is also iterative and requires a few rounds until you are satisfied the yolo model works, and will run on the edge.
Then deploy, sit back, have a sip of green tea. You've earned it